

Kubernetes is a portable, extensible, open-source platform for managing containerized workloads and services, that facilitates both declarative configuration and automation. It has a large, rapidly growing ecosystem. Kubernetes services, support, and tools are widely available.
The name Kubernetes originates from Greek, meaning helmsman or pilot. Google open-sourced the Kubernetes project in 2014. Kubernetes combines over 15 years of Google's experience running production workloads at scale with best-of-breed ideas and practices from the community.
In this post, I am going to explain the architecture of Kubernetes
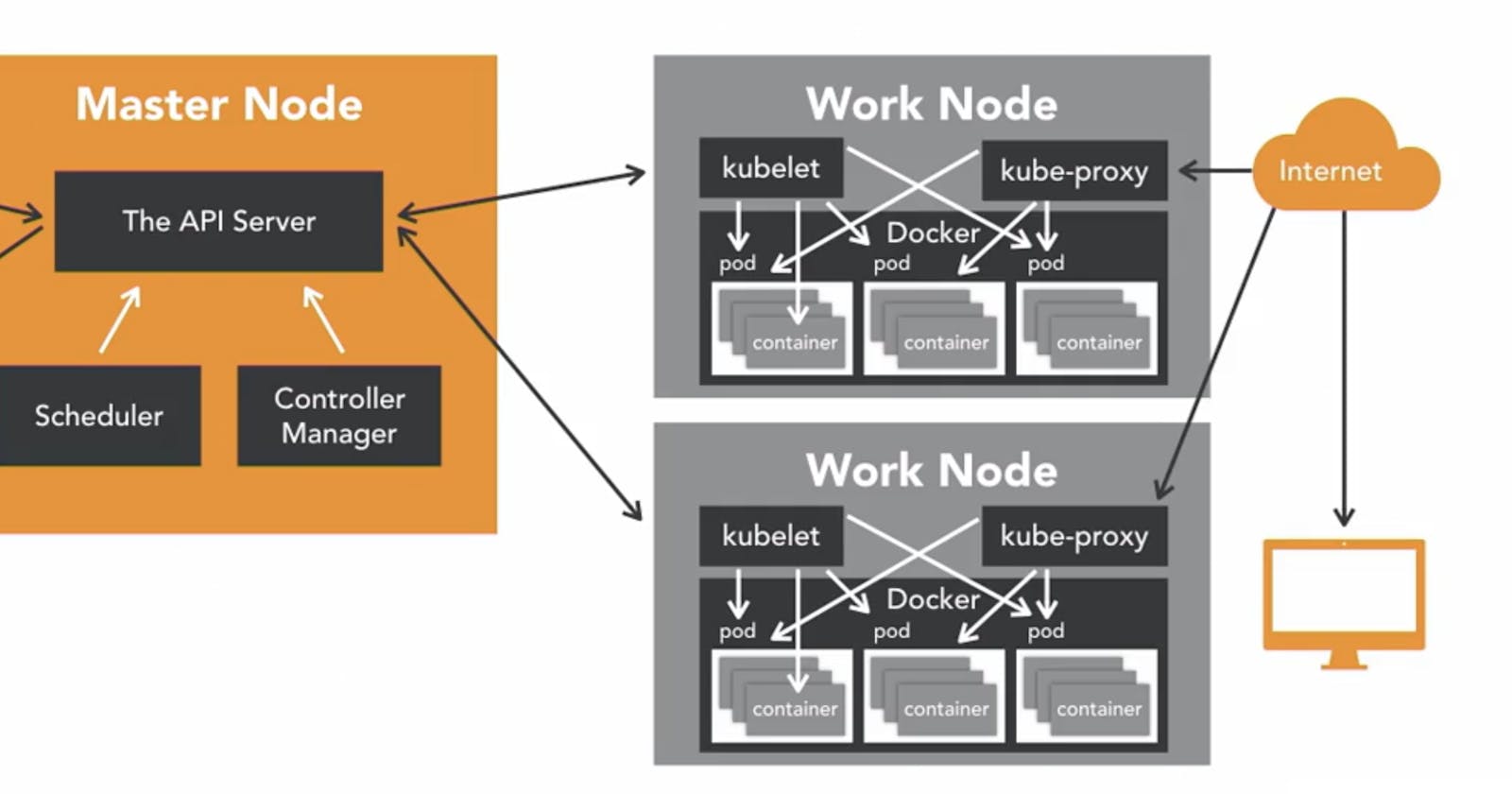
In the first step, we have the Master Node, and it is responsible for the overall management of the Kubernetes cluster. It got three components that take care of communication, scheduling, and controleer. These are The API Server,Scheduler, and Controller Manager.
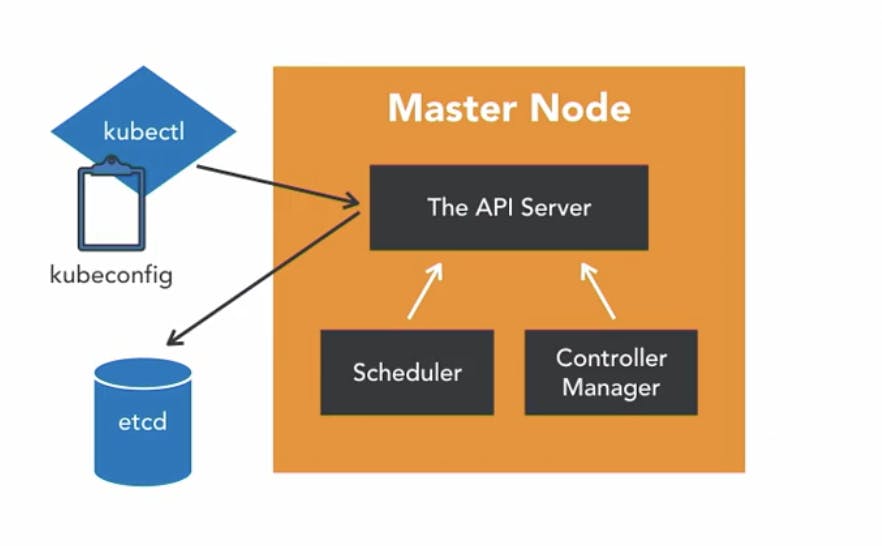
The API Server:
As the name states, it allows you to interact with Kubernetes API. It is the frontend of Kubernetes Control Plan
Scheduler:
The Scheduler watches the created pods that do not have any design yet and design the pods to run on a specific node.
Controller Manager:
The controller Manager run controller. These are background threads that run threads on the cluster. The controller has a bunch of different roles, but that all compiled into a single binary. The roles include,the node controller, who's responsible for the worker states, the replication controller, which responsible for maintaining the correct number of pods for the replicated controller. The endpoint controller, which joins service and pods together.
Service account and token controller that handles access management
Finally, there is etcd which is a simple distributed key-value store. Kubernetes uses etcd as a database and stores all cluster data. Some of the information which might be stored is job scheduling information, pod details, state information, etc.
kubectl is used to interact with The Master Node. It is a command-line interface for the Kubernetes. kubectl as a config file called as kubeconfig. this file has server information as well as authentication information to access The API Server
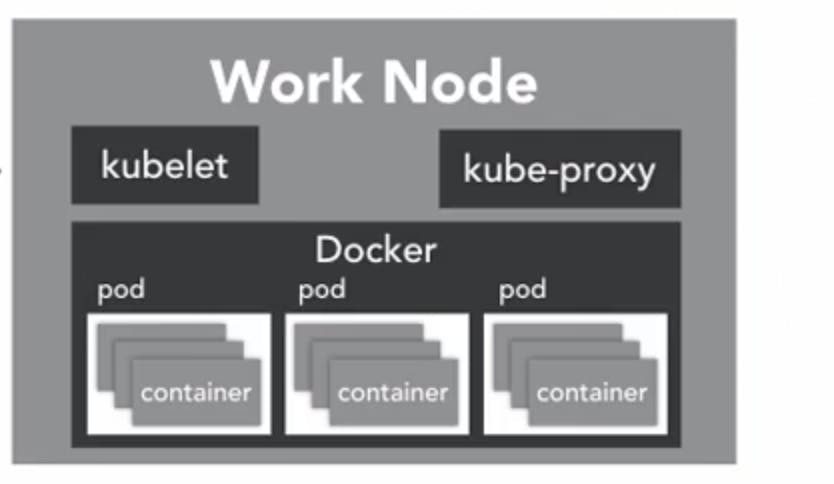
Worker Node
A node may be a virtual or physical machine, depending on the cluster. Each node contains the services necessary to run Pods, managed by the control plane.
The Worker Node is the node where the application operates. The Worker Node communicates back to the Master Node. Communication to worker node from Master Node is handled by the kubelet process.
Kubelet
It is an agent that communicates with the API Server to see if the pod has been designed for the node. it executes the pod container via the container engine. It mounts and runs pod volume secrets. Finally, it's away of pods and node states and responds back to master. Its save to say that if Kubelet is not working correctly in the Worker Node, you are going to have issues.
Kubernetes is container orchestration, so the expectation is that you have a container-native platform running on your worker node. This is where the docker comes in, and works together with kubelet to run the container on the node.
Kube-Proxy This process is the network proxy and load balancer for the service. on the single worker node, it handles the network routing for TCP and UDP packet, and it perform connection forwarding.
Having the docker daemon allows containers of an application are tightly coupled together in a pod
Pod A pod is the smallest unit that can be scheduled as deployment in a Kubernetes. It contains a group of containers that share storage, Linux name space, IP addresses among other things. there also co-located and share resources that all are scheduled together.
Once the pod has been deployed and running, the Kubelet process communicates with pods to check on state and healthy, and kube-proxy route and packet to the pods from other resources that might be wanting to communicate with them.
Worker node can be exposed to the internet via the load balancer, and traffic coming to worker node is also handled by Kube-Proxy which is how and end-user end up taking wih kubernetes applications
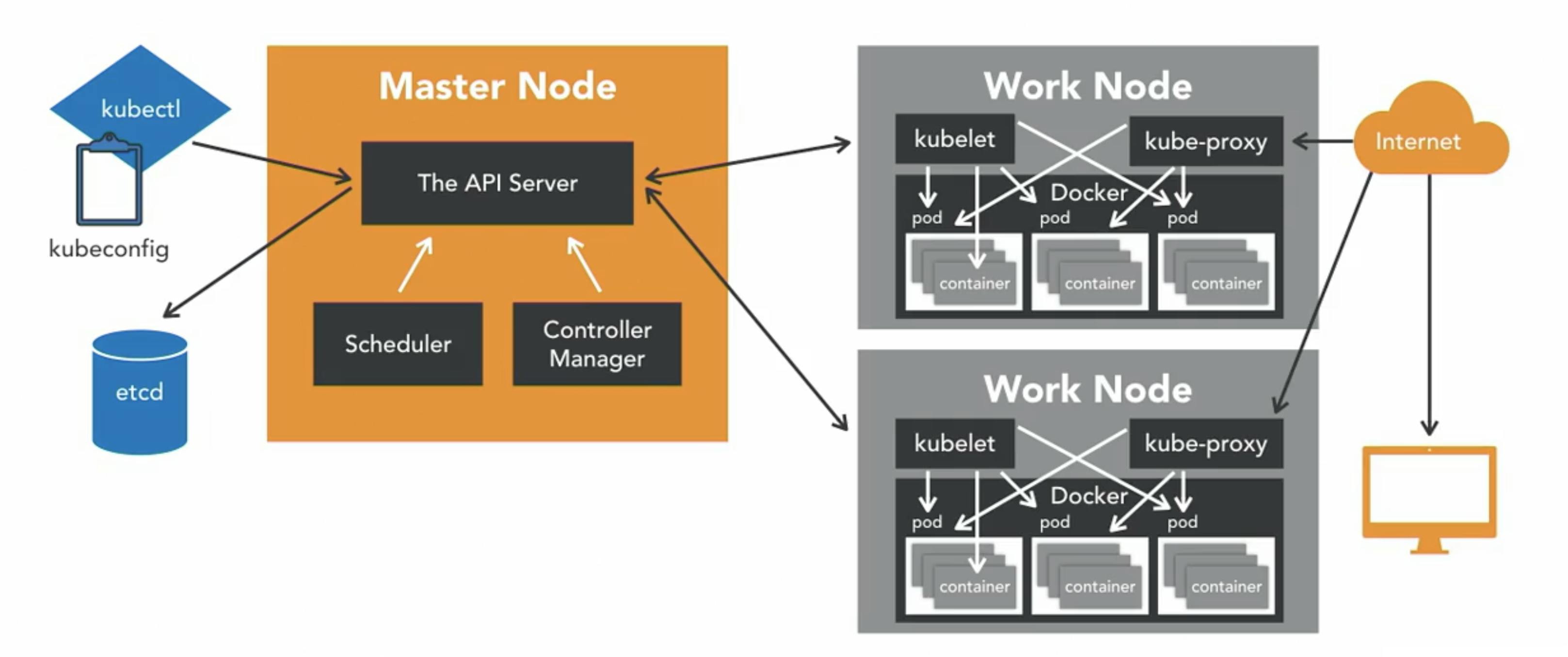
Summary
We have Master Node and Worker Nodes. On the Master Node, we have HDD cluster which stores information about the cluster, we have Scheduler to schedule application or containers onWorker Nodes. we have different controllers that take care of different functions like the node controllers, replication controllers, etc. We have the Kube API server that is responsible for orchestrating all operations within the cluster.
On the Worker Node, we have Kubelet that listens to the instructions from the Kube API Server and manages containers. Next, we have Kube-Proxy that helps in enabling communication between services within the cluster.